Introduction
ASP.NET web developers have
three built in options to store session state, namely, in-process memory, SQL
Server and State Server.
In-process memory offers the fastest performance but is
unsuitable for use in web server farms because the session data is stored in
the memory of the ASP.NET worker process.
SQL Server is an out of
process session state storage option that works with web server farms. It
stores session data in a SQL Server database. It is the most reliable option
but the least performing one. One major issue with this option is that quite
often developers want to cache data retrieved from a database in session state,
to reduce database lookups. SQL Server session state defeats this purpose,
because there is little performance gain in caching data retrieved from a
database, in a database.
State Server is an out of
process session state storage option that works with web server farms. It
stores session data in memory and delivers better performance than SQL Server.
This seems like a good compromise between the in-process option and the SQL
server options. It has some drawbacks, however.
Firstly, several web servers
typically depend on one state server for session state which introduces a
critical single point of failure.
Secondly, in
a load balanced environment, the load balancer may redirect a user’s request to
a web server that is different from the web server that served the user’s
previous request. If the new web server communicates with a different state
server, the user’s original session state will not be found and the web
application may not work properly.
This problem occurs even in persistence-based (aka sticky) load balancers
either erroneously or due to server failure.
Thirdly, an issue that many
developers are unaware about is that the web server and state server
communicate in plain text. An eavesdropper can easily get hold of session state
data traveling on the network. This may not be a threat if all servers are
running in an internal network but it is certainly cause for concern when web
servers and state servers are spread across the internet.
The peer to peer ASP.NET state server presented in this
write-up addresses the aforementioned problems while transparently replacing
the Microsoft provided state server.
Overview
The idea behind the peer to
peer state server is simple -- let state servers on a network securely
communicate and pass session state data amongst each other as needed, as shown
below.
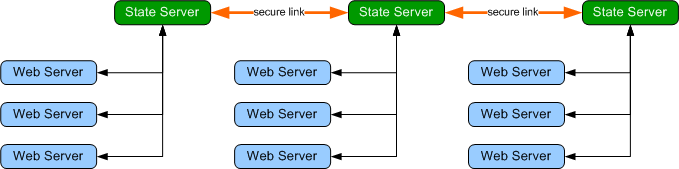
This design improves scalability because web servers can share multiple state
servers, eliminating a single point of failure. Furthermore, if a load balancer
erroneously or intentionally redirects a user to a different web server
attached to a separate state server, the user’s session state will be requested from
the state server that served the user’s previous request.
Security is also improved as
peers can be configured to encrypt session data while sharing session state.
Data transfers between the web server and the state server remain unencrypted
but eavesdropping attacks can be eliminated by keeping web servers and linked
state servers in trusted networks or on the same computer.
The peer to peer state server is
fully backward compatible with the Microsoft provided state server and comes
with all the benefits mentioned earlier.
Installation
To compile and
install the state server:
- Download the source file.
- Open up the solution in
visual studio. (Visual Studio 2008 will open up a Conversion Wizard.
Complete the Wizard.)
The state server comes in two flavors. One runs as a console application
and the other one runs as a windows service. The StateService
project compiles as a windows service and can be installed and uninstalled
with the install_service.bat and uninstall_service.bat
files. The ConsoleServer project runs the service as a console
application, which is a lot easier to test and debug. Both projects share
the same sources and function identically.
- Open up the properties window for the project you want to
build.
- a. If using Visual Studio 2005, add NET20 in the conditional
compilation symbols field of the Build tab.
b. If using Visual Studio 2008, select .NET Framework 3.5 in the
Target Framework field of the Application tab.
- Build the project.
- If you built the StateService project,
navigate to the output folder and run install_service.bat to
install the service.
- If you are already running the Microsoft state service on
your machine, stop it.
- If you built and installed the windows service, you can start Peer to
Peer State Service in the Services list. If you built the console
server, run ConsoleServer.exe or simply start debugging from Visual
Studio.
- You can now test and run any web applications you have
with the running state server.
To add peer servers:
- Copy the compiled executable file and the application
configuration file to another computer on your network.
- Open up the configuration file and add a new peer in the <Peers> section. For
instance, to configure the state server to connect to another state server
running on a computer named SV3 with a peer port number of 42425, you would add <add key="MyPeer" value="pc2:42425" /> to the <Peers> section.
- You can start the state server on the computer and it will
link up with the other state server(s) on the network.
- It’s up to you to set up the network in any topology you
like. For example, consider a network of three state servers as shown
below, each state server on each machine would have the configuration shown
below:
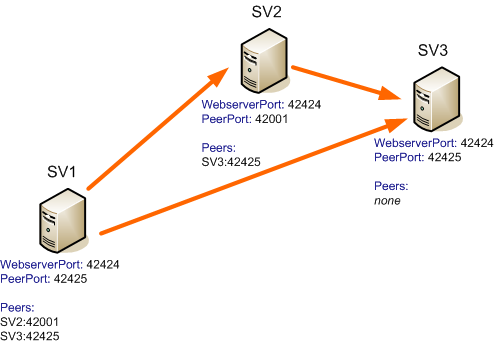
You can run multiple console server peers on the same
computer but each console server must have a unique web server port and peer
port setting.
How it works
The Microsoft provided state server, works as shown below.
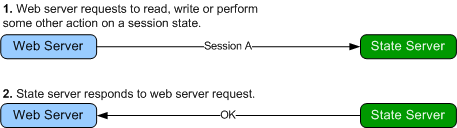
The Peer to Peer State Server works exactly as illustrated above, except when
the state server doesn't have the requested session state, in which case it
requests the session state from the network before responding, as illustrated
below:
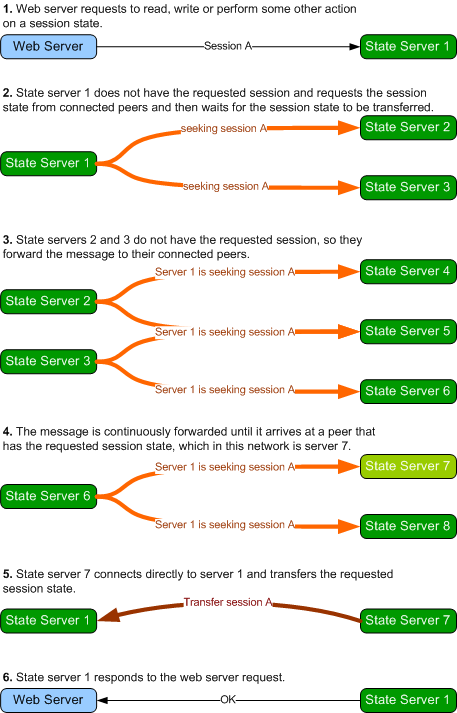
If the requested session state is
not transferred within a set time period, the state server assumes the session
state does not exist on the network and proceeds to process the web server
request without the session state. The GetTransferMessage class
represents the message that is broadcast on the network when a node is
requesting a session. Peers maintain connection between themselves principally
to forward this message. Session state transfers occur out-of-band of the peer
network.
Implementation Notes
Various programming techniques are used to implement
different aspects of the state server. Some of the notable ones are highlighted
below.
PLATFORM
The state server is written in C#
2.0 but targets the NET 3.5 framework so as to take advantage of the ReaderWriterLockSlim
class. If the NET20
symbol is defined, the server uses the slower ReaderWriterLock class
instead and is able to target the .NET 2.0 framework.
PROTOCOL
In order to create a state server
that can transparently replace the state server, I needed to obtain and understand the full
specification of the communication protocol between the web server and the
Microsoft provided state server. The steps taken to piece out the
protocol are documented in reverse chronology at http://ahuwanya.net/blog/category/Peer-to-Peer-Session-State-Service.aspx
MESSAGING
The server is largely message driven. The messaging
subsystem is illustrated below:
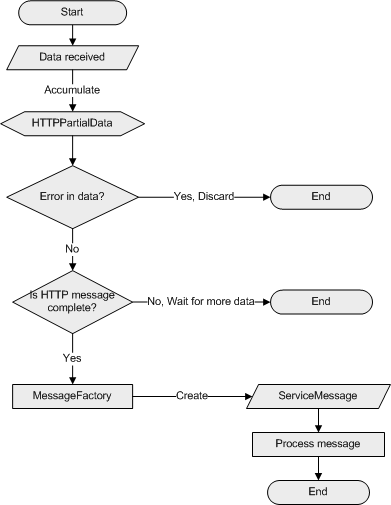
When the server receives data
from a socket, the data is accumulated in an instance of the HTTPPartialData
class currently assigned to that socket. The HTTPPartialData instance
validates the data, determines if the accumulated data is a complete HTTP
message and checks for errors in the accumulated data. If there is a
data error (for example, if the data does not conform to HTTP), the entire
accumulated data is discarded and the socket is closed. If the data is valid
but not yet complete, the sockets waits for more data to arrive.
If the accumulated data is a complete HTTP message, the data is sent to a MessageFactory
object. The MessageFactory object inspects the data to determine the
appropriate ServiceMessage child class instance to create.
The ServiceMessage child class is instantiated and its implementation of the Process
method is called to process the message.
CONCURRENCY HANDLING
A pessimistic concurrency
mechanism is employed while accessing session state in the session dictionary,
which is defined by the SessionDictionary class. A piece of session
state can only be read or modified by one thread at a time. A thread declares
exclusive access to operate on a piece of session state by setting the IsInUse
property to true. This is done by calling the atomic compare and swap CompareExchangeInUse
method (a wrapper to the .NET Interlocked.CompareExchange method that
operates on the IsInUse property). Setting this property to true
lets other threads know that another thread is working with that session state.
If another thread wants to access
the same session state and attempts to declare exclusive access, the attempt
will fail because another thread already has exclusive access. The thread will
keep trying to acquire exclusive access, and will eventually acquire it when the
other thread releases access. This works pretty well because most of the time, only
one thread needs to access a session state, and also because most operations on
a session state take a very short time to complete. The export (transfer) operation which takes a
much longer time is handled with a slightly different mechanism and is
discussed in the contention management section below.
TIMERS – OR THE LACK OF THEM
The code has a lot of objects
that expire or time-out and on which certain actions must take place on
expiration – objects like individual session state dictionary entries that expire or
asynchronous messages that timeout. Instead of assigning a timer or a wait
handle to track these objects – they are stored in instances of a special collection class
called the DateSortedDictionary. Objects in this dictionary are sorted
in place by their assigned timestamps. Specially designated threads poll these date sorted
dictionaries for expired items and perform related actions if an item is expired.
This design significantly reduces the number of threads needed to keep track of
expiring items.
DIAGNOSTICS
The Diags class is used to keep track of messages, log server
activity and detect deadlocks. Methods on the Diags class are
conditional and will not compile into release configuration code.
The VERBOSE symbol can be
defined to view or log all activity taking place at the server. This is
particularly useful with the console server which outputs this information to
the console window. If the VERBOSE
symbol is not defined, only critical information or unexpected errors are
displayed.
Security
The Microsoft provided state
server transmits and receives unencrypted data to and from the web server. This was
most likely done for performance reasons. To be compatible with the Microsoft
provided state server, the peer to peer state server transmits unencrypted data
to the web server. However the peer to peer state server can be configured to
transmit encrypted data between peers. This effectively thwarts network
eavesdropping attacks if web server and associated state servers are installed
on the same computer or on a trusted network.
For example, take the Web server – Microsoft State Server
configuration shown below.
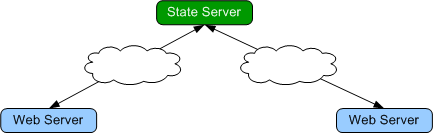
Two web servers connect across the public internet to access a state server.
Using peer to peer state servers, the network can be secured
by having the web servers have their own local state servers that connects
securely to the remote state server on their behalf as shown below:
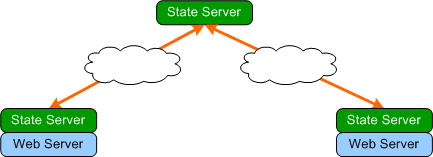
The local state servers can be installed on the same machine
as the web server for maximum security and minimum latency.
This approach can help secure geographically distributed web
and state servers.
Peer state servers also
mutually authenticate each other while connecting, to ensure that the other party is an
authorized peer.
Network Topologies
Connections between peers form logical networks which can be
designed with common network topologies in mind.
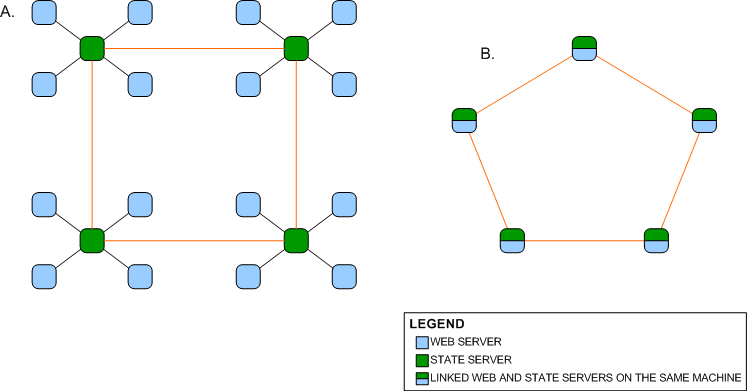
Network A shown above is a ring
network of peer state servers which are individually connected to web servers
whereas Network B is a ring network of computers which have both state server
and web server connected and running. Existing isolated Microsoft state server networks
can be upgraded to form a larger peer to peer network by replacing the Microsoft state servers with
peer to peer state servers and linking them up as shown in Network A. Network B
benefits from the security counter measures mentioned earlier and is somewhat
more scalable since any node on the network is a web server and a peer state
server.
Both networks will still function
if one node fails, unlike on a bus network, however as more nodes are added to
the network, the longer it takes for a message to traverse the network.
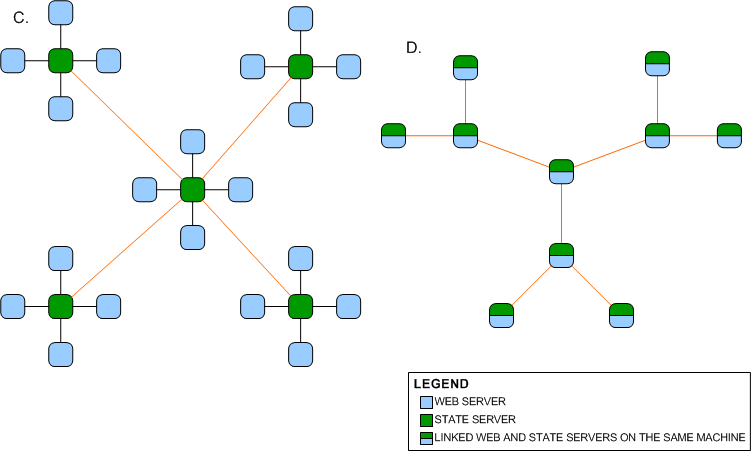
Network C is a star network. An
advantage of having a star network is that no matter how many new nodes are
added to the ring network, it takes only two hops for a message to reach any node on the
network.
Network D is a network of three
star networks that form a larger star network. This network too will require a
lesser number of hops for a message to traverse the network. Both networks
suffer from the disadvantage that if the central node fails, the entire network
fails.
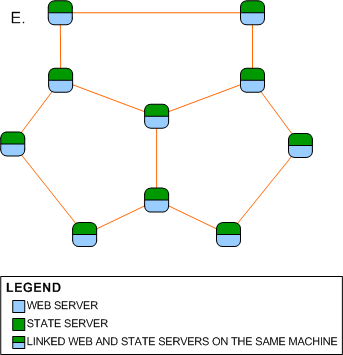
By connecting the leaf nodes on Network D,
Network E, a partial mesh network is formed. Network E is a clever combination of
a ring network and a star network. If the central node fails, the network will
still function and it also takes a fewer number of hops for a message to traverse the
network than on a ring network.
As demonstrated, the topology of
the peer to peer state server network is limited only by the imagination of the
network designer.
Interesting Scenarios
There are a lot of scenarios that
occur in the state server that are handled using traditional peer to peer
processes such as the time to live header which is used to prevent messages from circulating perpetually on the network, and message identifiers used by peers to recognize
messages that have been seen earlier, however, there are two particular scenarios that occur in this
peer network that are not so common.
SHUTDOWN TRANSFERS
To ensure that session data is not lost during a server shutdown,
the state server proceeds to transfer all its session state data to connected
peers in a round-robin fashion when a server shut down is initiated.
REBROADCASTS
A request for a session on a network can narrowly miss the
node holding the session if it is being transferred it as illustrated below.
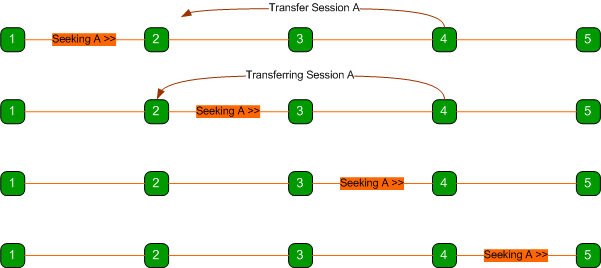
As shown above, node 1 is seeking
session A from the network just about the same time node 4 wants to transfer
the session to node 2.
When the message from node 1 reaches node 2,
node 2 forwards the message to node 3 because it doesn’t have the session.
When the message reaches node 3, the session transfer between nodes 4 and 2
begins and by the time the message reaches node 4, the transfer is complete and
node 4 no longer has the session anymore and forwards the message to node 5.
Thus, the message traverses the
network without reaching any node with the sought session, even though the
session exists on the network.
The state server addresses this issue by having nodes that
recently transferred a session rebroadcast the message as shown below.
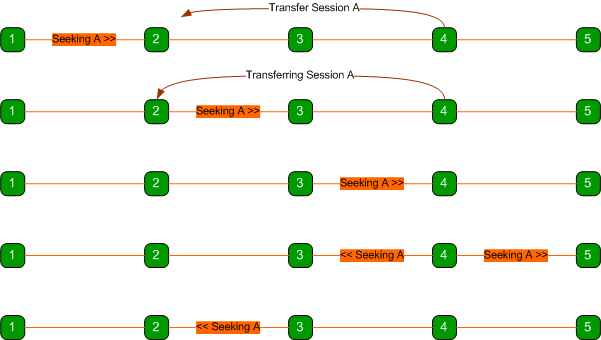
Here, node 4 rebroadcasts the
message so that it also travels back the way it came and eventually reaches
node 2 which has the session.
Rebroadcasted messages are
duplicates of the original message except that they have a different Broadcast
ID header which peers use to know it’s a different broadcast.
Contention Management
As stated earlier, the state server
uses a pessimistic concurrency model when accessing session state entries in the session dictionary. This
works well because most requests take a short time to process. However, one
particular request can take a much longer time to process, and can lead to
resource starvation and performance degradation.
A GetTransferMessage
message broadcast is initiated by a peer when it needs to work with a
session state it does not have. When the broadcast reaches a peer with the
requested session state, the session state is transferred to the requesting
peer.
Unlike other operations on a
session state, a transfer can take a significant amount of time because the
peer has to connect to the other peer, possibly authenticate, and transmit (a
potentially large amount of) data. It’s important to note that any
request from the web server can kick start a GetTransferMessage broadcast.
During a transfer, the session is
marked as “in use” and other requests on that session will have to wait as
usual. However, since it takes a much longer time, Threads waiting for a
transfer operation to complete consume a lot of system resources. They can also
timeout if the transfer takes too long or if the session is repeatedly
transferred around the network due to flooded messages. A bad case is
illustrated below:
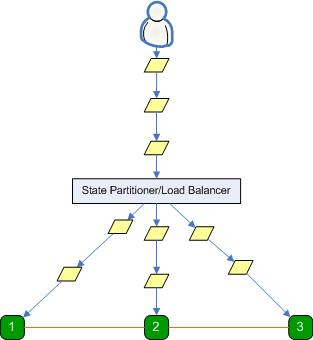
In the diagram above, a user is
flooding a web application with requests, which in turn is causing session requests
to be transmitted to a state server.
Because all requests originate
from one user, all session requests reference the same session id. A load
balancer or state partitioner distributes these requests among the three
state servers.
It is important to note that even though it is
unlikely that a load balancer or state partitioner will distribute requests for
a session among different state servers, a user can produce the scenario shown
above by simply pressing and holding the browser refresh key on a web
application that uses a poorly implemented state partitioner or a
malfunctioning load balancer.
Also, an organized group of malicious users (or a botnet)
can produce this scenario even on properly functioning state partitioners and
load balancers.
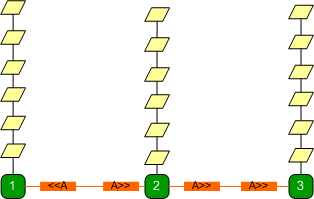
Each state server has requests
waiting to be processed. If the highly in-demand session is say, on state server 3,
requests on that state server will be processed one by one very quickly.
State servers 1 and 2 issue
broadcasts requesting a session transfer. The message eventually reaches state
server 3 and the request is transferred to say state server 2. Requests on
state server 3 that were not processed will wait until the transfer is
complete.
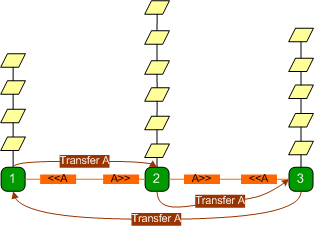
After the session transfer to
server 2 is complete, requests on server 2 are processed, whereas requests on
server 3 issue broadcasts requesting the session.
A broadcast that originated from
state server 1 reaches state server 2 and the session is transferred to state
server 1. This goes on and on and the servers keep transferring the session
amongst themselves while most of the requests wait, because even when a session
is transferred, the state server is only able to process a few requests before
it is transferred to another state server.
To make matters worse, if a state
server receives a GetTransferMessage message after it has recently
transferred the session, it rebroadcasts the message (as explained earlier), which leads to even more
GetTransferMessage broadcasts on the network, more back-and-forth transfers and
prolonged resource starvation.
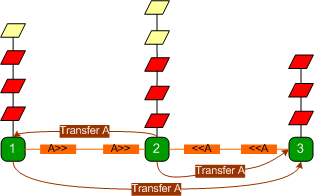
The transfer process is
relatively slow and since all requests have to wait to be processed one at a
time by each state server, requests start to time out and the web server starts
discarding requests. The state server is unaware that the web server has
discarded those requests and still proceeds to process them.
These redundant requests, waiting
for their turn, eat up valuable server processor cycles and degrade the quality
of service.
If plenty of these requests arrive,
they'll quickly use up all processor resources and the server comes to a
grinding halt.
While it may be impossible to
stop any group of users from flooding the state server with requests, the state
server guards against contentious sessions with the following principle: any
degradation of service due to a contentious session should mainly affect the
user of that session, and achieves this goal with the following mechanisms:
- When a
request is to be processed and the server notices the session is being
transferred, the request stops being processed and is queued to be
processed when the transfer is over. This prevents the request from
eating up processor cycles while waiting, and frees up
resources, so that other requests from other users can be processed. If
the number of requests on a queue waiting for a session to transfer is
too long, then all those messages are discarded because it means the
session is contentious and the server shouldn't bother processing them.
- After the
transfer is complete and a queued request is ready to be reprocessed and
the server notices that the same session is been transferred again by
another request, then the request will be discarded and not be processed,
because it means the session is highly contentious.
- Before a
request tries to query the network (by broadcasting) for a session, it
checks if it is expecting a reply from a previous query for that session,
and if so, the request is queued to a list of requests to be processed
when the query is received. This reduces the number of GetTransferMessage
messages that will be generated on the network, which in turn reduces
unnecessary rebroadcasts and lookups. If the number of requests on a
queue waiting for a session to arrive is too long, then all those
requests are discarded because it means the session is contentious.
- Finally, all incoming requests
are queued up in their session id-specific queue and the message
processor polls the incoming request queues in a round-robin manner and
processes them one after the other, as shown below:

This means that all session requests are treated fairly, no single user
can significantly disrupt the rate at which messages originating from other users are
processed. Additionally, if the queue for a particular session id is too
long, that queue is discarded because it means that session is
contentious.
All these techniques employed by
the state server can only adversely affect the web application of the offending user.
Conclusion
The peer to peer state server is
fully backward compatible with the Microsoft provided state server and can
transparently replace it. Peer state servers can transfer sessions to each
other, improving the reliability of session state dependent web applications.
Peer state servers also act as a security layer that protects session data on the
network.
This project started out as a
simple idea but quickly evolved into a complex task. Hopefully, this
implementation and other ideas presented in this article will be valuable to
developers interested in distributed systems. Due to the level of
complexity, there will be bugs and kinks to work out. Contributions and bug reports
will be appreciated.